はじめに
Amazon CloudWatch Network Monitorは、2023年12月22日に一般提供開始されたサービスであり、AWS~オンプレミス間のネットワークがモニタリング可能となります。
自らのハイブリッドネットワーキング業務から導き出した、公式ドキュメントにも載っていないNetwork Monitorのユースケースおよび仕様についてご紹介します。
本記事でもサービス概要は触れていますが、基本的なサービス仕様は公式ドキュメントなどでご確認頂けますと幸いです。
Network Monitorとは
Network Monitorは、AWS上のサブネットからオンプレミスにTCPもしくはICMPポーリングを行い、遅延およびパケットロス率を取得します。
構成は、1つのモニタにつき単一もしくは複数の送信元サブネットと送信先IPアドレスを指定すると、すべての組み合わせのプローブ(=トラフィック)が作成されます。
その他、インターバル、メッセージサイズ、ポートなどのパラメータも指定できます。詳しいパラメータは前述の公式ドキュメントをご参照下さい。

Network Monitorユースケース
グレー障害の検知および対処
従来のトラフィックに関わるログやメトリクスでも、ネットワークの切断や通信影響は確認できるのでは?と思われる方もいらっしゃるかもしれません。
ハイブリッドネットワーキングで利用されるDirectConnet、Site-to-Site VPN、TGW (VGWのログやメトリクスは存在しない) で収集可能なログやメトリクスを以下に整理してみました。
正常もしくは異常を示す状態、ビットレートやパケットレートなどの通信量を示す情報が多く見受けられ、一見すると充実してそうです。
| メトリクス | 説明 |
|---|---|
| DirectConnect Connection | |
| DirectConnect VIF | |
| Site-to-Site VPN |
|
| Transit Gateway | |
| Transit Gateway Attachment |
| ログ | 説明 |
|---|---|
| Site-to-Site VPN |
ただ上記のログやメトリクスでは、システムが完全停止するのではなく、一部停止もしくはパフォーマンス低下するグレー障害を検知することが難しいです。
ネットワークにおけるグレー障害は、通信機器のソフトエラーやハードエラー等によって大幅な遅延や断続的な通信断を引き起こします。

大幅な遅延や断続的な通信断によって、業務通信はエラーが発生するがBGPは再送処理で救済されて状態が変化しない、また通信量も全部流れないわけでなく一部流れるため異常検知できません。
また、 Amazon CloudWatch anomaly detection機能を利用する場合でも、不規則なトラフィック特性を持つ通信では誤検知が増えてしまい、かえって運用負担が大きくなる可能性があります。
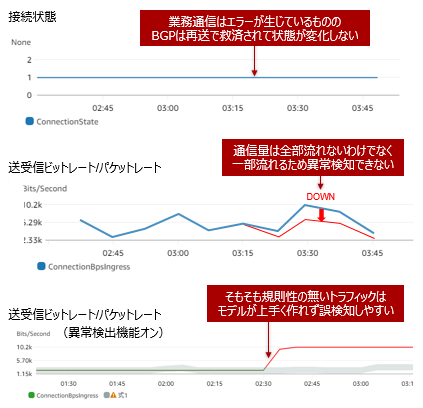
対処策として、Network Monitorの遅延およびパケットロス率評価が有効です。
グレー障害発生時におけるメトリクス変化幅が大きく、正常と異常の閾値を定義しやすいためです。理由としては、DirectConnectはトラフィック品質が安定しており、遅延が変化しにくくパケットロスも通常発生しないためです。

閾値を超過した場合には、CloudWatchアラームでトリガーし、BGPフェイルオーバーも可能です。
DirectConnectサービスのBGPフェイルオーバーテスト機能を利用しますが、最大72時間でフェイルバックするため、その後のアクションは予め決めておくと良いでしょう。詳しくは以下の記事でご紹介してますので、ご興味をお持ちになった方は是非ご参照下さい。
疎通テスト
ネットワークリーチャビリティを確認したい場合におけるAWSサービスと言えば何でしょうか?Reachability Analyzerがパッと思い浮かぶ方は多いのではないでしょうか。
ハイブリッドネットワークを構築・運用する場合には、以下の仕様に従ってReachability Analyzerで疎通性を解析できません。
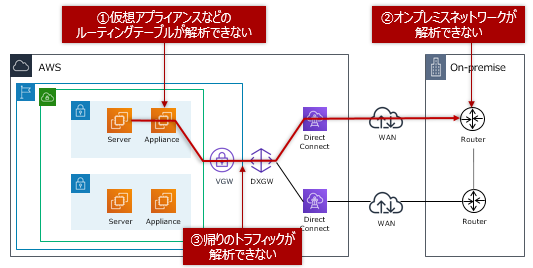
あくまでハイブリッドネットワーキングで解析できないだけであって、VPCネットワーキングの疎通テストでは大変有用なサービスだと思います。
とはいえ、その他にも解析できないケースもありますので、ご利用される方は以下のドキュメントをご一読されることをお勧めします。
対処策として、Network Monitorの疎通テスト活用が有効です。
遅延やパケットロス率を取得する用途でないため賛否両論があると思いますが、送信元はマネージドサービス・送信先はエージェントレスと使い勝手も良く、労力を抑えて疎通性を確認できます。また、机上確認でなく実際にトラフィックを流すため、結果に対する信用度もより高いです。

もしNetwork Monitorの結果がNGだった場合は設定見直しと並行し、AWSであればVPCフローログ、オンプレミスであればACLカウンターなどでパケット有無を切り分けます。
VPCフローログは、デフォルトでなくカスタムでなければ確認できないフィールドもありますので、ご利用される方は以下のドキュメントをご一読されることをお勧めします。
Network Monitor仕様
ポーリングインターバル
モニタ作成時に1分もしくは30秒を選択しているのでは?と思われるかもしれませんが、その選択肢はポーリングインターバルでなく集計インターバルです。
この仕様へ気付いたきっかけは、ポーリング開始よりごく僅かな時間しか経ってないにも関わらず、パケットロス率が0.x%と細かく刻んだことでした。
パケットキャプチャした結果、30秒あたり600発、つまりポーリングインターバルは50ミリ秒であることが確認できました。

データの量が多いため、検知の精度が桁違いの高さです。
例として、BGPとNetwork Monitorで検知の精度を比較した結果を以下に示します。パケットロス率が結構高めでも、BGPは中々検知できないことがお分かりいただけるかと思います。
| BGP | Network Monitor | |
|---|---|---|
| 条件 | パケットロス率: 10% キープアライブ: 10秒 ホールドタイマー: 30秒 |
パケットロス率: 10% 集計インターバル: 30秒 アラーム閾値: 5% |
| 30秒間で検知可能な確率 | 0.1% | ほぼ100% |
インターネット回線を用いたSD-WANではインターネット回線の信頼性が高くないため、このような遅延やパケットロス率に基づきフェイルオーバーします。
DirectConnectもグレー障害で受ける影響次第で、このような仕組みの導入検討が必要と思います。
送信元ENI
送信元ENIは、送信元サブネット数だけ必要でしょうか、もしくはプローブ数だけ必要でしょうか?答えとしては何れの数でもありません。
この仕様へ気付いたきっかけは、サブネットの空きアドレスが少なく、アドレスが枯渇しそうな状況でENIを確認したことでした。
ENIおよびVPCフローログを確認した結果、送信元ENIは送信元サブネット数×2で冗長化され、アドレス×2から同一の宛先へポーリングされてました。

上記のようにアドレスが枯渇しそうな場合には注意しましょう。
送信元ENIが冗長化される仕様は致し方ないのですが、サブネットあたりのプローブ数のクオータは上限緩和可能のためリクエストを検討してもよいかもしれません。
2023年11月5日時点ではNetwork Monitorは東京リージョンで対応しているものの、大阪リージョンで対応していませんのでご注意下さい。
詳しい対応リージョンは前述の公式ドキュメントをご参照下さい。
まとめ
自らのハイブリッドネットワーキング業務から導き出した、Amazon CloudWatch Network Monitorのユースケースおよび仕様をご紹介しました。
おわりに
Amazon CloudWatch Network Monitorは大変有用なサービスだと思います。より沢山の方々にご利用いただけるように、本記事が少しでも役立ちましたら幸いです。